| 發刊日期 |
2010年12月
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 標題 | 談高中新教材中機率統計的缺失與改進 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 作者 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 關鍵字 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 檔案下載 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 全文 |
在高中98數學課綱之機率統計新教材中, 其課程設計和教材編寫不但忽視學生的認知, 甚至在教科書上仍然存在一些錯誤的概念。 例如, 在介紹二項分配前對超幾何分配隻字不提, 導致優秀學生把簡單的超幾何分配問題利用二項分配來處理, 教師在課堂教學時如何改進這項缺失? 其次, 在提到中央極限定理的時候, 每本教科書都指出它是非常重要的定理, 但卻又認為超出高中範圍不宜多作說明, 難道就沒有通俗簡單的方式讓學生理解嗎? 至於錯誤的觀念部分, 有些教科書將信心水準定義為母體百分比 $p$ 會落在信賴區間的機率。教科書的使用攸關全國十幾萬的高中生, 這種錯誤之統計概念竟然會出現在經過審核的教科書上, 也難怪在98年學測中一道有關信心水準的試題,不但學生看了以後感到一頭霧水, 甚至連老師都不知道要如何選擇正確答案。雖然到目前為止數學教育研究還沒有建立一套標準, 但經過各方討論初步有一點已達成共識, 那就是: 數學教育研究必須走進課堂解決教與學的實際問題。本文將透過台北市一所高中在課堂中進行實際教學, 針對以上的缺失與錯誤儘量用通俗易懂的方式提出解決之道, 以提供給有興趣的學生與教師作為參考與改進的依據, 更盼望能在制定99課綱中得到更多的迴響, 以嘉惠於廣大青年學子為幸。 一. 超幾何分配與二項分配的關係筆者翻遍98年高中教科書的機率統計內容, 發現每一本都只提到二項分配, 而對於更簡單的超幾何分配卻隻字不提。 或許有學者會認為在實務上所面臨超幾何分配可被二項分配作極佳的逼近, 但站在基礎數學教育的觀點是不能這樣處理的, 就像常態分配可以很好的近似於二項分配, 難道我們也不需要學習二項分配了嗎? 為了暸解新教材的這種內容安排對學生有什麼影嚮, 筆者曾經對學過高三機率統計的自然組學生提出下列問題: 年終為了替孤兒院的孩子募集壓歲錢, 百貨公司印製了100張彩券義賣, 已知彩券中50% 是有獎品的。今某人購買了3張彩券, 問恰有2張中獎之機率 $=$? 在全班48人的答案中, 有39人之答案為 $C^3_2\Big(\dfrac 12\Big)^2\dfrac 12=\dfrac 38$, 有6人答案為 $\displaystyle{\frac{C^{50}_2C^{50}_1}{C^{100}_3}}=\frac{25}{66}$, 有2人計算出其他答案, 有1人空白未予以作答。 本題從調查資料結果顯示, 竟然有高達 81% 學生直觀的將之視為二項分配問題, 研究中為了進一步追蹤比較不同程度的學生反應, 又再度對已學過高三機率統計的社會組學生, 在一份問卷中同時提出下列兩個問題:
班上32人答案中, 第一題有31人答案為 $C^3_2\Big(\dfrac 12\Big)^2\dfrac 12=\dfrac 38$, 有1人之答案為 $1-(0.125\times 2)-(0.375)=0.375$; 第二題有19人的答案為 $C^3_2\Big(\dfrac 12\Big)^2\dfrac 12=\dfrac 38$, 有12人的答案為 $\displaystyle{\frac{C^{50}_2C^{50}_1}{C^{100}_3}}=\frac{25}{66}$, 有1人空白未予以作答。從這兩次的問卷結果可以看出, 把兩個不同問題同時並列提出讓學生作答, 對於一般平均數學程度較差的社會組, 有大約 38% 學生意識到兩個問題的差異性, 轉而更仔細的去思考問題的意義, 因而做出了較高比率的正確答案, 使得藉由直觀所產生的錯誤降為 59%。 由此可以證實教學過程中之問題經由適當的設計, 確實可以降低學生在學習機率概念的一些直觀錯誤。 上述所提兩個問題其實就是二項分配 (Binomial distribution) 與超幾何分配 (Hypergeometic distribution) 的概念, 從問卷結果中顯示它們是學生極易產生混淆的兩個觀念。 為了釐清這兩種分配所呈現問題的差異, 教學時筆者採取了鷹架教學 (Scaffolding instruction) 的方法, 讓學生透過師生對話討論出正確的想法。 課堂上提出下列問題與學生作對話式討論: 百貨公司年終印製彩券義賣, 已知彩券中有一半是有獎品的, 請問購買3張有2張中獎之機率 $=$? 學生A: 買3張有2張中獎之機率 $P=C^3_2\Big(\dfrac 12\Big)^2\dfrac 12=\dfrac 38$。 學生B: 我認為不能確定其機率, 因為我們根本不知道公司印了幾張彩券? 學生C: 憑直覺我認為不管印幾張都沒關係, 每種情況中獎機率應該都是 $\dfrac 12$。 學生D: 若印4張彩券時, 買3張恰中2張之機率 $P=\dfrac{C^2_2C^2_1}{C^4_3}=\dfrac 12$, 若印6張彩券時, 買3張恰中2張之機率 $P=\dfrac{C^3_2C^3_1}{C^6_3}=\dfrac 9{20}$, 所以我贊成B同學的想法。 筆者: 既然我們不知道彩券印幾張, 那同學不妨假設印了 $2n$ 張, 再計算取3張恰中2張的機率看看嘛! 學生D: 照老師的講法從 $2n$ 張中取 3 張恰中 2 張之機率 $P_n=\dfrac{C^n_1C^n_2}{C^{2n}_3}=\dfrac {3n^3-3n^2}{8n^3-12n^2+4n}$, 會隨著 $n$ 不同而得到不同答案。 筆者: 同學想一想當 $n$ 趨近於無限大時, 你們有沒有發現 $P_n$ 的值會趨近於多少呢? 學生A: 好奇怪喔! $\lim\limits_{n\to\infty} P_n=\lim\limits_{n\to\infty}\dfrac {3n^3-3n^2}{8n^3-12n^2+4n}=\dfrac 38$, 答案竟然跟我利用 $C^3_2\Big(\dfrac 12\Big)^2\dfrac 12=\dfrac 38$ 一樣耶! 至此, 學生已經開始慢慢體會出本題已不是單純的二項分配問題。 由於考慮學生相關先備知識 (Preknowledge)之不足, 在證明超幾何分配與二項分配關係前, 筆者先提出下面基本問題讓學生作為比較其差異性的鷹架: 袋中有紅球6個和白球3個, 今由袋中每次任取一球, 請問 (1) 在取後不放回的情況下, 連取 5 次得 3 紅球之機率 $=$? (2)在取後又放回的情況下, 連取 5 次得 3 紅球之機率 $=$? 這時有學生求出情形(1)的機率 $P=\dfrac{5!}{3!2!}\cdot \dfrac{6}{9}\cdot \dfrac{5}{8}\cdot \dfrac{4}{7}\cdot \dfrac{3}{6}\cdot \dfrac{2}{5} =\dfrac{10}{21}$, 筆者告訴學生取後不放回 使得每次取到紅球或白球之機率不恆相同, 這種機率模型稱為超幾何分配 (Hypergeometic distribution), 超幾何分配之每次試驗並非獨立。也有學生求出情形(2)的機率 $P=C^5_3\Big(\dfrac 69\Big)^3\Big(\dfrac 39\Big)^2$ $=\dfrac {80}{243}$, 筆者此時特別強調取後再放回可視為袋中有無限多個球, 使得每次取到紅球之機率恆 為 $\dfrac 69$ 而取到白球之機率恆為 $\dfrac 39$, 這種機率模型為二項分配 (Binomial distribution), 二項分配之每次試驗都是獨立的。 經過上面一連串的討論與說明之後, 才正式提出兩種機率分配的定義, 並證明超幾何分配之極限是二項分配的事實(丁村成, 1997)。
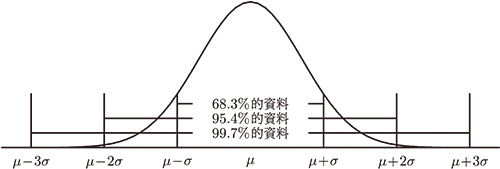
底下進一步向學生證明 : 當 $N\to \infty$ 時 $$\dfrac{C^M_rC^{N-M}_{n-r}}{C^N_n}\to C^n_r\Big(\dfrac MN\Big)^r\Big(1-\dfrac MN\Big)^{n-r}\hbox{。}$$ \begin{eqnarray*} \dfrac{C^M_rC^{N-M}_{n-r}}{C^N_n}&=&\displaystyle\dfrac{\dfrac{M!}{(M-r)!r!}\cdot \dfrac{(N-M)!}{(N-M-n+r)!(n-r)!}}{\dfrac{N!}{(N-n)!n!}}\\[5pt] &=&\frac{M!}{(M-r)!r!}\cdot \frac{(N-M)!}{(N-M-n+r)!(n-r)!}\cdot\frac{(N-n)!n!}{N!}\\[5pt] &=&\frac{n!}{(n-r)!r!}\cdot \frac{M\cdots(M-r+1)}{N^r}\cdot\frac{(N-M)\cdots (N-M-(n-r)+1)}{N^{n-r}}\\[5pt] &&\cdot \frac{N^n}{N(N-1)\cdots(N-n+1)}\\[5pt] &=&\frac{n!}{(n-r)!r!}\Big(\frac MN\cdots \frac{M-r+1}N\Big)\Big(\frac {N-M}N\cdots \frac{N-M-(n-r)+1}N\Big)\\[5pt] &&\cdot \Big(\frac NN\frac N{N-1}\cdots \frac N{N-n+1}\Big) \end{eqnarray*} 當 $n$, $r$ 固定時因為 \begin{eqnarray*} \lim_{N\to\infty}\frac{M}{N}\cdot \frac{M-1}{N}\cdots \frac{M-r+1}{N}&=&\lim_{N\to\infty}\frac{M}{N}\cdot \lim_{N\to\infty}\frac{M-1}{N}\cdots \lim_{N\to\infty}\frac{M-r+1}{N}\\[5pt] &=&\lim_{N\to\infty}\frac{M}{N}\cdot \lim_{N\to\infty}\Big(\frac{M}{N}-\frac 1N\Big)\cdots \lim_{N\to\infty}\Big(\frac{M}{N}-\frac{r-1}{N}\Big)\\[5pt] &=&\lim_{N\to\infty}\Big(\frac{M}{N}\Big)^r \end{eqnarray*} 而且 \begin{eqnarray*} &&\hskip -25pt \lim_{N\to\infty}\frac{(N-M)(N-M-1)\cdots(N-M-(n-r)+1)}{N^{n-r}}\\[5pt] &=&\lim_{N\to\infty}\frac{N-M}{N}\cdot \lim_{N\to\infty}\frac{N-M-1}{N}\cdots \lim_{N\to\infty}\frac{N-M-(n-r)+1}{N}\\[5pt] &=&\lim_{N\to\infty}\Big(1-\frac{M}{N}\Big)\cdot \lim_{N\to\infty}\Big(1-\frac{M}{N}-\frac 1N\Big)\cdots \lim_{N\to\infty}\Big(1-\frac{M}{N}-\frac{n-r-1}{N}\Big)\\[5pt] &=&\lim_{N\to\infty}\Big(1-\frac{M}{N}\Big)^{n-r} \end{eqnarray*} \begin{eqnarray*} \lim_{N\to\infty}\frac{N^n}{N(N-1)\cdots(N-n+1)}&=&\lim_{N\to\infty}\frac{N}{N}\cdot \lim_{N\to\infty}\frac{N}{N-1} \cdots\lim_{N\to\infty}\frac{N}{N-n-1}\\[5pt] &=&1\cdot 1\cdots 1=1 \end{eqnarray*} 因此得到 當 $N\to \infty$ 時 $\dfrac{C^M_rC^{N-M}_{n-r}}{C^N_n}\to C^n_r\Big(\dfrac MN\Big)^r\Big(1-\dfrac MN\Big)^{n-r}$ 最後, 筆者舉了一道生活中的應用問題, 讓學生瞭解上述結論在實際上的應用: 工廠之 1000個產品中的不良品比率為0.1, 從其中任意抽取 3 個產品出來,請問恰有一個不良品之機率 $=$? 由超幾何分配得其機率 $P\!=\!\dfrac{C^{100}_1\cdot C^{900}_2}{C^{1000}_3}\fallingdotseq 0.2434598$, 但產品的樣本數量頗大而不易 計算, 若用二項分配近似於超幾何分配, 可得其機率 $P=C^3_1(0.1)(0.9)^2=0.243$。因此, 可以看出在 $N$ 很大的情況下, 利用二項分配算出的機率與超幾何分配非常接近。 二. 二項分配近似於常態分配之教學自然界有許多事物的分佈情形都有一個特徵, 就是數值資料大多集中於其平均數附近, 而位在兩個極端的資料數量並不多, 且它們都會均勻分佈在平均數的左右兩邊。 例如: 某一地區居民的總收入, 某一學校學生之數學成績 $\cdots\cdots$ 等等, 其分佈曲線都是呈現單一高峰的左右對稱曲線, 這種曲線稱為常態曲線 (Normal curve)。常態曲線有一個最高點, 此點的橫座標就是資料的平均數 $\mu$, 曲線的左右兩端會對稱於 $x=\mu$, 而資料的離散程度可以用標準差 $\sigma$ 描述。一般只要我們知道了平均數與標準差, 整個資料的常態曲線就完全被確定了, 其中的平均數決定了曲線的中心, 而標準差確定了曲線的形狀。在統計上只要樣本資料符合常態曲線, 這些樣本分佈在範圍 $[\mu-\sigma,\mu+\sigma]$、 $[\mu-2\sigma,\mu+2\sigma]$、 $[\mu-3\sigma,\mu+3\sigma]$之比率大約為 68.3%、 95.4%、 99.7%, 我們稱之為常態分配的經驗法則 (Empirical rule), 亦即約有 68.3% 的資料會落在距平均數一個標準差內; 約有 95.4% 的資料會落在距離平均數兩個標準差內; 約有99.7% 的資料會落在距平均數三個標準差內, 如下圖。
在 1733 年棣美弗 (De Moivre) 首先由二項分配 (Bionomial distribution) 的逼近推出了常態分配 (Normal distribution) 之表達式 $f(x)=\displaystyle\frac{1}{\sqrt{2\pi}\sigma}e^{\frac{-(x-\mu)^2}{2\sigma^2}}$ (王幼軍, 2007)。 但他當時二項逼近的工作並未引起人們的重視, 使得常態分配也僅停留於數學表達的層面, 在實際應用中也沒有找到適合存活的土壤。陳希孺認為, 棣美弗本人並不是一位統計學家, 他並未從統計學的觀點去考慮這項逼近工作的意義, 其出發點僅把 $p$ 作為已知數去研究如何用二項分配逼近常態分配, 而不是將 $p$ 看作未知數並通過觀察結果對它進行推論 (陳希孺, 2005)。 因此, 在 棣美弗時代要使常態分配成為一種機率模型的時機尚不成熟, 但他對二項分配與常態分配的研究成果讓中央極限定理之發展有著承先啟後的作用。 正是在此基礎上拉普拉斯 (Laplace)於1780年對棣美弗的結果進行推廣, 並建立了棣美弗$-$拉普拉斯極限定理 (De Moivre-Laplace Limit Theorem)(Hald, 1998)。 進入十八世紀數學出現一個很重要的特徵, 那就是數學研究的目標在於處理人類碰到之實際問題, 生活中無論對自然現象或社會現象進行觀測, 總會產生誤差這一點在很早以前人們就注意到了, 但是對於其觀測值所呈現的隨機性人們卻認識模糊。 雖然歷史上有很多天文學家和數學家曾對誤差理論作過研究, 但都沒有從棣美弗的著作中得到任何有關常態分配的啟發。 直到1809年高斯(Gauss)在研究測量誤差之機率分配時, 才讓棣美弗所發表的常態分配表達式得到了機率分配的身份, 又因高斯對常態分配所作的研究對後世的影嚮極大, 使得後人對於常態分配又有高斯分配的稱呼 (Hald, 1998)。 德國10馬克的紙鈔上曾印有高斯肖像與常態分配的圖案, 這表示數學王子高斯一生中在科學上, 對於全人類最大的貢獻就是常態分配。 在二項分配近似於常態分配的高中教材中, 有教科書是利用投均勻硬幣20次中會出現幾次正面, 然後讓全班每位同學投一硬幣20次, 可能有人會擲出 8次正面也有人可能擲出12次正面, 如果將每人所擲出的正面次數記錄下來, 那麼這些次數之平均數就相當接近10次, 最後就直接得出結論: 機率裡的期望值就是統計試驗中大量數據的平均值。也有教科書先利用EXCEL計算二項分配再寫一些連老師都看不下去的計算式子, 然後利用二項分配的期望值與標準差求比率 $p$ 的 95% 信賴區間, 我真不知道編者有沒有考慮到教與學之問題。 至於在教導高中學生的時候要如何來表達這個概念呢? 以下是個人在課堂中之教學片斷, 首先介紹二項分配的期望值與標準差。 對於每次只有成功與失敗兩種結果的試驗中, 若繼續重複作 $n$ 次試驗且每次試驗是獨立的, 則在 $n$ 次中恰有 $k$ 次成功的機率為 $P=C^n_kp^k(1-p)^{n-k}$, 這種機率分配我們稱之為具有參數 $(n,p)$ 的二項分配。在具有參數 $(n,p)$ 的二項分配中若令 $X$ 表示其成功次數, 則有下列結論:
證明如下:
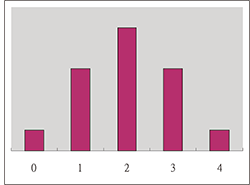
\begin{eqnarray*} \hbox{$X$ 的期望值} \mu&=&E(X)=\sum_{k=0}^n kC^n_kp^k(1-p)^{n-k}\\ &=&\sum_{k=0}^n \dfrac{k\cdot n!}{k!(n-k)!} p^k(1-p)^{n-k}\\ &=&\sum_{k=1}^n \dfrac{n!}{(k-1)!(n-k)!} p^k(1-p)^{n-k}\\ &=&np\cdot \sum_{k=1}^n \dfrac{(n-1)!}{(k-1)!(n-k)!} p^{k-1}\cdot(1-p)^{n-k}\\ &=&np[p+(1-p)]^{n-1}\\ &=&np\\[5pt] \hbox{$X^2$ 的期望值} E(X^2)&=&\sum_{k=0}^n k^2\cdot C^n_k\cdot p^k\cdot (1-p)^{n-k}\\ &=&\sum_{k=0}^n k(k-1)\cdot C^n_k\cdot p^k\cdot (1-p)^{n-k}+\sum_{k=0}^n k\cdot C^n_k\cdot p^k\cdot (1-p)^{n-k}\\ &=&\sum_{k=0}^n \dfrac{k(k-1)\cdot n!}{k!(n-k)!} p^k\cdot (1-p)^{n-k}+np\\ &=&\sum_{k=2}^n \dfrac{n!}{(k-2)!(n-k)!} p^k\cdot (1-p)^{n-k}+np\\ &=&n(n-1)p^2\sum_{k=2}^n \dfrac{(n-2)!}{(k-2)!(n-k)!} p^{k-2}\cdot (1-p)^{n-k}+np\\ &=&n(n-1)p^2[p+(1-p)]^{n-2}+np\\ &=&n(n-1)p^2+np \end{eqnarray*} 因此我們得到 \begin{eqnarray*} \hbox{$X$ 的標準差} \sigma&=&S_X=\sqrt{E(X^2)-E^2(X)}\\ &=&\sqrt{n(n-1)p^2+np-(np)^2}\\ &=&\sqrt{np(1-p)} \end{eqnarray*} 關於常態分配是二項分配的近似, 為了讓學生很快的瞭解這個重要的概念, 筆者在上課中簡單提出了一個 $p=\dfrac 12$ 與 $p\not=\dfrac 12$ 的例子說明如下: 一. 投擲一公正硬幣 4 次, 令 $X$ 表示在 4 次試驗出現的正面次數, 求 $P(X=k)=$?
並作其二項分配機率圖形如右:
\begin{eqnarray*}
P(X=0)&=&C^4_0(\dfrac 12)^0(\dfrac 12)^4=\dfrac 1{16}\hskip 7cm~\\[5pt]
P(X=1)&=&C^4_1(\dfrac 12)^1(\dfrac 12)^3=\dfrac 4{16}\\[5pt]
P(X=2)&=&C^4_2(\dfrac 12)^2(\dfrac 12)^2=\dfrac 6{16}\\[5pt]
P(X=3)&=&C^4_3(\dfrac 12)^3(\dfrac 12)^1=\dfrac 4{16}\\[5pt]
P(X=4)&=&C^4_4(\dfrac 12)^4(\dfrac 12)^0=\dfrac 1{16}
\end{eqnarray*}
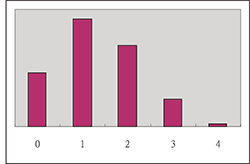
二. 投擲一公正骰子 4 次, 令 $X$ 表示在 4 次中出現一點或四點之次數, 求 $P(X=k)$ 並作其二項分配機率圖形如右: \begin{eqnarray*} P(X=0)&=&C^4_0(\dfrac 13)^0(\dfrac 23)^4=\dfrac {16}{81}\hskip 7cm~\\[5pt] P(X=1)&=&C^4_1(\dfrac 13)^1(\dfrac 23)^3=\dfrac {32}{81}\\[5pt] P(X=2)&=&C^4_2(\dfrac 13)^2(\dfrac 23)^2=\dfrac {24}{81}\\[5pt] P(X=3)&=&C^4_3(\dfrac 13)^3(\dfrac 23)^1=\dfrac 8{81}\\[5pt] P(X=4)&=&C^4_4(\dfrac 13)^4(\dfrac 23)^0=\dfrac 1{81} \end{eqnarray*}
由上面例題我們可以告訴學生, 當具有參數 $(n,p)$ 之二項分配中的 $n$ 足夠大時 $(n\ge 30)$, 它會近似於平均數 $\mu=np$, 標準差 $\sigma=\sqrt{np(1-p)}$ 之常態分配, 課堂上只要對 $n$ 逐漸增大加以說明或配合電腦模擬實驗, 根據我的經驗學生很容易接受這個事實。 此一觀念是機率中計算繁瑣二項機率的重要依據, 但由於其機率牽涉到近似的概念, 所以在評量學生問題的時候, 最好採選擇型式並配合近似的觀念來命題。例如: 投擲一枚不公正銅板72次, 其出現正面的機率為 $\frac 13$, 則此硬幣出現正面次數介於 16 次與 32 次之間的機率最接近下列何者? (A) 0.64 (B) 0.68 (C) 0.80 (D) 0.95 (E) 0.99 解: 令 $X$ 表示出現正面之次數, 則出現正面次數介於 16$\sim$32 次之機率為 \begin{eqnarray*} P(16\lt X\lt 32)&=&P(X=17)+P(X=18)+\cdots+P(X=31)\\ &=&C^{72}_{17}\Big(\frac 13\Big)^{17}\Big(\frac 23\Big)^{55}+C^{72}_{18}\Big(\frac 13\Big)^{18}\Big(\frac 23\Big)^{54}+\cdots +C^{72}_{31}\Big(\frac 13\Big)^{31}\Big(\frac 23\Big)^{41} \end{eqnarray*} 這是一個非常繁瑣的式子, 我們必須另謀其他方法求機率值。但當試驗次數 $n$ 足夠大時二項分配會近似於常態分配, 本題出現正面的次數 $X$ 近似於 $\mu=np=72\Big(\frac 13\Big)=24$, $\sigma=\sqrt{72(\frac13)(\frac 23)}=4$ 之常態分配, 因此可以得到其機率 \begin{eqnarray*} P(16\lt X\lt 32)&=&P(\mu-2\sigma\lt X\lt \mu+2\sigma)\\ &=&0.954 \hbox{最接近上述答案中的} 0.95 \end{eqnarray*} 有關二項分配近似於常態分配就是歷史上的棣美弗$-$拉普拉斯極限定理, 它告訴我們當二項分配的參數 $n$ 足夠大時, 可利用常態分配來求其近似值。此定理首先由棣美弗在1733年證明出 $p=\frac 12$ 的情形, 後來才由拉普拉斯將其結果推廣到一般的 $p$, 其中 $0\lt p\lt 1$。 此定理敘述如下(丁村成, 1997):
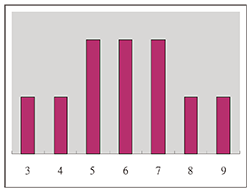
三. 中央極限定理通俗的表達方式中央極限定理(Central Limit Theorem)是連接機率與統計之重要橋樑, 它指出: 從具有平均數 $\mu$ 與標準差 $\sigma$ 的母體 (Population) 中隨機取出 $n$ 個樣本 $X_1,X_2,\ldots,X_n$, 當 $n$ 足夠大時 $\bar X=\frac 1n\sum_{i=1}^n X_i$ 的抽樣分配會近似於平均數 $\mu$ 而標準差 $\frac \sigma{\sqrt{n}}$ 之常態分配。 至於樣本數 $n$ 要多大才能使得常態分配給 $\bar X$ 之抽樣分配提供更良好的近似呢? 其答案依賴於被抽樣的母體而定, 但一般對於大多數母體取樣本數 $n\ge 30$ 是足夠的 (Mc Clave et al. 2008)。 目前的高中教科書介紹這個定理大都採取了電腦摸擬加以說明, 但這並無助於學生對此一重要定理的瞭解, 因為學生從電腦模擬中無法親自體會 $\bar X$ 抽樣分配之隨機性。上課中為加深同學對 $\bar X$ 這個分配之個數及變化, 我特別設計了下面問題來說明。 從母體 0, 3, 6, 9, 12 中任意抽取三個樣本 $X_1,X_2,X_3$, 求出所有可能樣本平均數 $\bar X=\frac 13\sum_{i=1}^n X_i$ 之抽樣分配並繪出其抽樣分配機率圖形為何? 首先可由 $C^5_3=10$ 得知我們共可抽出十組不同的樣本, 因此也會得到十種 $\bar X$ 的不同情形, 將之列表並計算每一組之 $\bar X$ 如下:
若將 $\bar X$ 按大小順序排列可得到其對應的機率分配如下表:
因此, 可以繪出 $\bar X$ 抽樣分配之機率圖形於下:
此抽樣分配 $\bar X$ 之平均數 \begin{eqnarray*} E(\bar X)&=&\frac 1{10}(3+4+5+6+7+8+9)=\frac 1{10}(60)=6 \end{eqnarray*} 若利用除以 $n$ 的公式得 $\bar X$ 的標準差 \begin{eqnarray*} S_{\bar X}&=&\sqrt{\frac 1{10}[(3\!-\!6)^2+(4\!-\!6)^2+(5\!-\!6)^2+\cdots+(8\!-\!6)^2+(9\!-\!6)^2)]}\\ &=&\sqrt{\frac 1{10}(9+4+1+1+0+1+0+1+4+9)}=\sqrt{\frac 1{10}(30)}=\sqrt{3}\fallingdotseq 1.73\\ \end{eqnarray*} 這個例子不但可讓學生瞭解 $\bar X$ 抽樣分配的平均數與標準差不易求得, 亦可使他們體會到 $\bar X$ 抽樣分配對於 $n=3$ 的情形已具有常態分配之趨向, 這就是給予中央極限定理很直觀的視覺化 (Visualization) 表達方式。 要證明 $\bar X$ 的平均數 $E(X)=\mu$ 與標準差 $S_{\bar X}=\frac \sigma{\sqrt{n}}$ 並不難, 因為 \begin{eqnarray*} E(\bar X)&=&E\Big(\frac{X_1+X_2+\cdots+X_n}n\Big)=\frac 1n\sum_{i=1}^n E(X_i)\\ &=&\frac 1n\sum_{i=1}^n \mu=\frac 1n\cdot n\mu=\mu\\[5pt] S_{\bar X}&=&\sqrt{Var\Big(\frac{X_1+X_2+\cdots+X_n}n\Big)}=\sqrt{\frac 1{n^2}\sum_{i=1}^n Var(X_i)}\\ &=&\sqrt{\frac 1{n^2}\sum_{i=1}^n \sigma^2}=\sqrt{\frac 1{n^2}\cdot n \sigma^2}=\sqrt{\frac{\sigma^2}n}=\frac\sigma{\sqrt{n}} \end{eqnarray*} 最後再提出中央極限定理的結論: 從具有平均數 $\mu$ 及標準差 $\sigma$ 之母體中隨機取出 $n$ 個樣本, 當 $n$ 足夠大時樣本平均數 $\bar X$ 的抽樣分配會近似於平均數 $\mu$ 及標準差 $\frac\sigma{\sqrt{n}}$ 之常態分配。 個人透過實際教學大部分學生都能清楚此定理的意義, 此一教法更有助於讓學生正確掌握信心水準的觀念。 至於比較一般的中央極限定理之形式如下(Ross, 2006):
這是拉普拉斯最早所提出的一般形式, 但他本人對此定理的證明並不十分嚴格。 真正嚴格的證明是李雅普諾夫(Lyapunov)在1901$\sim$1902年之間所完成, 並在證明中首創利用了嶄新的特徵函數 (Characteristic function), 透過特徵函數方法實現了機率分析的革新, 才使得機率中有關極限定理的證明得到更大的發展(Adams, 2009)。 中央極限定理早期的應用顯示測量誤差近似於常態分配, 這在科學上發展出很多非常重要的貢獻, 所以十七世紀至十八世紀它通常被稱為誤差頻率定律 (Law of frequency of errors)。 至於「The Central Limit Theorem」這個名稱, 是由波利亞(Polya)於 1920 年在其博士論文中所提出的。 四. 信賴區間與信心水準之正確解讀在選舉前有民調中心想要調查某位候選人的支持度, 最準確的方法當然是調查所有合格選民, 若在 $N$ 個會去投票者中有 $M$ 個支持該候選人, 則其真正的支持度 $p=\frac MN$ 即為母體支持率。 但是這樣的調查方法往往耗費太多的人力與物力, 根據統計學一般會採取隨機的方式進行抽樣調查。 為估計未知的母體支持度 $p$, 民調中心隨機抽取了一份 $n$ 個人的樣本, 若調查結果有 $m$ 個人支持這位候選人, 則其樣本之支持率 $\hat p=\frac mn$, 這只是對該候選人支持率的一個估計。如果重新隨機再抽取 $n$ 個人的樣本, 由於組成另一個樣本的人不一定與上次相同, 使得對該候選人的支持率 $\hat p$ 也可能隨之改變。因此, 在抽取 $n$ 個樣本的抽樣中可產生 $C_n^N$ 組不同的樣本, 則對該候選人的樣本支持率 $\hat p$ 就可能有 $\frac 0n, \frac 1n, \frac 2n,\ldots, \frac nn$ 不同變化, 其發生的機率分別列表如下:
因此可得到 \begin{eqnarray*} \hat p \,\hbox{期望值}\, E(\hat p)&=&\sum_{k=0}^n \frac kn C^n_kp^k(1-p)^{n-k}=\frac 1n\sum_{k=0}^n kC^n_kp^k(1-p)^{n-k}\\ &=&\frac 1n \cdot np=p\end{eqnarray*} \begin{eqnarray*} {\hat p}^2 \,\hbox{期望值}\, E({\hat p}^2)&=&\sum_{k=0}^n \Big(\frac kn\Big)^2 C^n_kp^k(1-p)^{n-k} =\frac 1{n^2}\sum_{k=0}^n k^2 C^n_kp^k(1-p)^{n-k}\\ &=&\frac{1}{n^2}[n(n-1)p^2+np]=\frac{(n-1)p^2+p}n\\[5pt] \therefore\ \hat p \,\hbox{的標準差}\,\sigma&=&\sqrt{E({\hat p}^2)-[E(\hat p)]^2}=\sqrt{\frac{(n-1)p^2+p}{n}-p^2}\\ &=&\sqrt{\frac{p(1-p)}{n}} \end{eqnarray*} 根據中央極限定理當 $n$ 足夠大時, $\hat p$ 產生的分配會趨近於平均數 $p$ 與標準差 $\sqrt{\frac{p(1-p)}{n}}$ 之常態分配, 再由常態分配的經驗法則可得知 $\hat p$ 值有大約95% 的比例會落在 $\Big[p-1.96\sqrt{\frac{p(1-p)}{n}},p+1.96\sqrt{\frac{p(1-p)}{n}}\Big]$。 一般在抽樣時我們並不知道母體真正值 $p$, 但當抽取樣本數 $n$ 足夠大時, 每一組樣本所產生的 $\hat p$ 都會近似於 $p$, 所以也可以利用 $\hat p$ 來估計 $p$, 我們稱 $\Big[\hat p-1.96\sqrt{\frac{\hat p(1-\hat p)}{n}},\hat p+1.96\sqrt{\frac{\hat p(1-\hat p)}{n}}\Big]$ 為 $p$ 的 95% 信賴區間 (Confidence interval)。 因為統計學家有某種程度的信心認為該區間會包含 $p$, 所以給它取名為信賴區間, 其理由是當我們收集了許多不同的樣本, 並對每個樣本都得到了一個信賴區間, 這些信賴區間有足夠的信心使其中的 95% 包含了母體之真正值, 則 95% 這個值就被稱為信心水準 (Confidence level)(Iversen, et al.~1997)。 95% 這個值在統計是比較常用的, 當然你也可以使用其他值 90% 或 99% 來作信心水準。 在大多數情況下, 調查人員收集數據時都只取一組樣本, 可是沒有人能夠知道這組樣本所產生的信賴區間是否包含 $p$。 至於這個區間是否包含 $p$ 呢? 注意! 它只有兩種答案, 即它包含 $p$ 或不包含 $p$, 採用機率的觀點來看就是 $P\Big(p\in \Big[\hat p-1.96\sqrt{\frac{\hat p(1-\hat p)}{n}},\hat p+1.96\sqrt{\frac{\hat p(1-\hat p)}{n}}\Big]\Big)=1$ 或 0, 亦即信心水準 95% 並不是一個機率值, 所以不可以將之解讀為真正 $p$ 值會落在此信賴區間的機率是 0.95。 因此, 統計學上才假設做了足夠多次抽樣後, 借助其近似於常態分配的經驗法則來探討信心水準, 並創造出信賴區間這樣的名詞來描述它。我們之所以用這種拐彎抹角的表達方式, 其原因在於母體真正值是未知的固定數, 而抽樣比率 $\hat p$ 所得到的信賴區間卻是變動的, 若重複這個作法會得到一些不同的信賴區間, 在這個意義下信賴區間是一個隨機區間, 此區間會隨著所取樣本的不同而不同。 一個區間就像為了捕獲未知的 $p$ 而撒出去的網, 並非每一次撒網的地點都能捕獲真正值 $p$。 因此, 信心水準 95% 的意義是多次抽樣中大約有 95% 的信賴區間會包含未知的母體真正值 $p$, 或通俗的解讀為我們大約有 95% 的「信心」 確定這次調查得到的信賴區間會包未知的母體真正值 $p$。在98年學測考試有一道題目:
本題大考中心公佈的正確答案為選項(1)(2), 並統計全體考生答對率只有 7% 而鑑別度為 $-0.01$。 雖然題目在敘述上之用字遣詞不是非常完美, 但個人對於這題的命題委員之用心表示欽佩, 因為他在選項(4)中點到了未知殺手 $p$, 也在選項 (5) 中考慮到了 $\hat p$ 的隨機性。 如果學生未能瞭解 $p$ 的未知性與 $\hat p$ 之隨機性, 那就無法對這兩個選項作出是否正確的判斷, 這也是個人一再強調教師在使用中央極限定理之前, 必須對抽樣分配 $\bar X$ 的隨機性作一番解說, 才能讓學生對於理解 $\hat p$ 的隨機性有所幫助。 在目前各版本教科書對此觀念都語焉不詳的情況下, 我實在不敢指望學生能夠瞭解選項(4)與(5)的意義。 筆者建議教師在課堂中將本題改成下面題目, 對於學生在理解此一概念會有更好的效果:
本題筆者設計其正確選項為(1)(2)(4)。切記! 電腦在數學教學上只是一種幫助瞭解與計算的輔助工具, 如果在教學的過程中處處依賴電腦而不深入思考, 根據數學教育一些相關研究結果已經表明, 這對於學習抽象與推理能力將是有害無益的, 這也是為什麼有教科書趕時髦附上隨機區間電腦模擬實驗, 卻又在書上寫出「$p$ 落在信賴區間的機率稱為信心水準」這種不合理的定義了。(98年9月筆者曾向該教科書編輯群提出這項錯誤, 但直到99年2月數學四修訂版232頁還是存在這個定義。在這次修訂版的定義下雖加註了「信心水準與機率兩者有不同涵義」, 卻於同書241頁又作了一些和此定義自相矛盾的說明, 令人不解與遺憾。) 五. 參考資料---本文作者為數學教育博士, 目前積極參與數學教育理論與實踐之研究--- |
2010年12月 34卷4期
談高中新教材中機率統計的缺失與改進